Spesso è possibile visualizzare la seguente domanda nei gruppi di supporto tecnico di Firebird: "Qual è l'hardware scelto per Firebird DBMS?". Questo argomento rimane permanentemente popolare perché i requisiti hardware differiscono per attività e l'hardware stesso cambia nel tempo.
Abbiamo deciso di scrivere questa guida per fornire le conoscenze necessarie a chiunque desideri scegliere hardware veramente efficace per il proprio database Firebird. Per farlo, dovrai imparare alcuni dettagli di base su come funzioni Firebird, il sistema operativo e, ovviamente, l'hardware.
Per scoprire quale hardware si adatta meglio al tuo database Firebird, dobbiamo capire come Firebird utilizza i suoi componenti: CPU, RAM, HDD / SSD e come questi componenti interagiscono con il sistema operativo (ad esempio, con la cache dei file).
Prima di tutto, esamineremo i moduli funzionali di Firebird con l'aiuto della Figura 1:
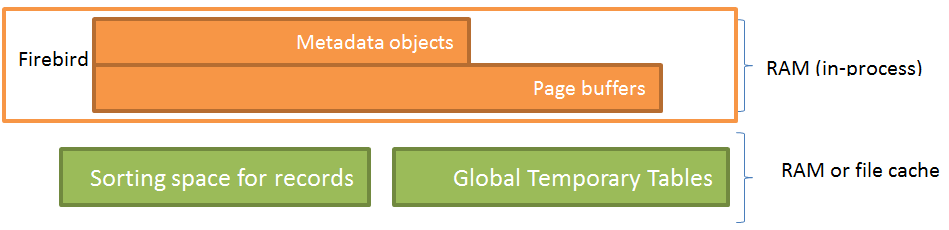
Figura 1. Moduli Firebird
Firebird include i seguenti moduli funzionali principali:
Vediamo come i moduli funzionali Firebird interagiscono con i componenti hardware durante le operazioni eseguite nel corso dell'utilizzo dei database.
Una volta avviato Firebird, il processo del server occupa la quantità minima di RAM (diversi megabyte) e non esegue alcuna operazione intensiva con la CPU o la RAM.
Quando viene stabilita una connessione al database, il server inizia a leggere i suoi metadati e crea gli oggetti corrispondenti in memoria, con il risultato che il processo richiede più risorse più tabelle, indici, trigger e altri metadati vengono utilizzati. L'utilizzo della memoria aumenta, ma la CPU non è praticamente utilizzata in questa fase.
Quando il client inizia a eseguire query SQL (comprese le stored procedure), il server esegue le operazioni corrispondenti utilizzando l'hardware. È possibile individuare le seguenti operazioni di base che comportano l'interazione con l'hardware:
Ognuna di queste operazioni richiede una certa quantità di risorse di sistema. La tabella seguente mostra il consumo di risorse in unità intense (1 significa meno intenso, 10 significa più intenso):
| Reading a page from the disk | Writing a page to the disk | Reading a page from the page buffers cache | Writing a page to the page buffers cache | Reading from a GTT | Writing to a GTT | Sorting records | Processing SQL queries | |
| CPU | 1 | 1 | 1 | 1 | 1 | 1 | 5 | 10 |
| RAM | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 2 |
| Disk I/O | 10 | 10 | 1 | 1 | 1 | 1 | 1 | 1 |
Come puoi vedere, le operazioni che richiedono più risorse sono quelle che comportano l'accesso al disco perché i dischi rimangono il componente hardware più lento nonostante i progressi negli ultimi anni relativi agli SSD.
Questo porta a uno dei modi per ottimizzare le prestazioni totalmente legate all'hardware: portare tutte le operazioni di lettura / scrittura su RAM. Tuttavia, l'approccio di aumento della cache della pagina non funziona. Tratteremo questo problema in dettaglio nella sezione RAM.
Di solito, è necessario scegliere l'hardware per un server che servirà molti client, quindi è davvero importante capire come viene implementato il parallelismo delle operazioni.
Dal punto di vista dei componenti hardware, possiamo parlare dell'uso parallelo della CPU, del disco e della RAM. Le moderne CPU hanno diversi core in grado di eseguire serie di istruzioni in parallelo, quindi il server DBMS distribuisce le operazioni tra i core, il che significa che più core ha la CPU, più client saranno in grado di lavorare su questo server.
Non è così semplice dal punto di vista dei dischi. Quando i tradizionali dischi rigidi (HDD) leggono le informazioni, spostano fisicamente la testa sul materiale magnetico a una velocità limitata. Un database può essere piuttosto grande, ovvero 3 terabyte di dimensione, e se le query SQL dai client accedono ai suoi dati situati in diverse aree del disco in parallelo, la testa del disco salterà tra le diverse aree del disco, rallentando notevolmente operazioni di lettura e scrittura. Aumenterà considerevolmente la coda del disco mentre il resto delle risorse (CPU, RAM) è inattivo. Naturalmente, la cache del disco (la cache dell'HDD o del controller RAID) compensa in parte questo rallentamento, ma non è sufficiente.
A differenza dei tradizionali HDD, le unità a stato solido (SSD) sono molto meno inclini al degrado delle prestazioni in caso di accesso parallelo ai dati. Il vantaggio di un SSD è particolarmente evidente quando si scrivono dati in parallelo: i nostri test mostrano che un SSD è 7 volte più veloce di un disco SATA (link!). Tuttavia, gli SSD presentano alcuni problemi che devono essere presi in considerazione durante il loro utilizzo (consultare Selezione dei dischi) al fine di evitare rallentamenti, guasti anticipati e perdita di dati.
Le operazioni con RAM vengono eseguite molto velocemente sui computer moderni, sono praticamente limitate solo dalla larghezza di banda del bus dati, quindi queste operazioni non agiscono come un collo di bottiglia anche se ci sono molte query SQL parallele.
Durante l'esecuzione di query SQL, Firebird legge e scrive molti dati, trasferendoli tra moduli funzionali e componenti hardware corrispondenti. Per identificare possibili colli di bottiglia, dobbiamo capire come viene effettuato lo scambio di dati. La Figura 2 che segue ci aiuterà in questo:
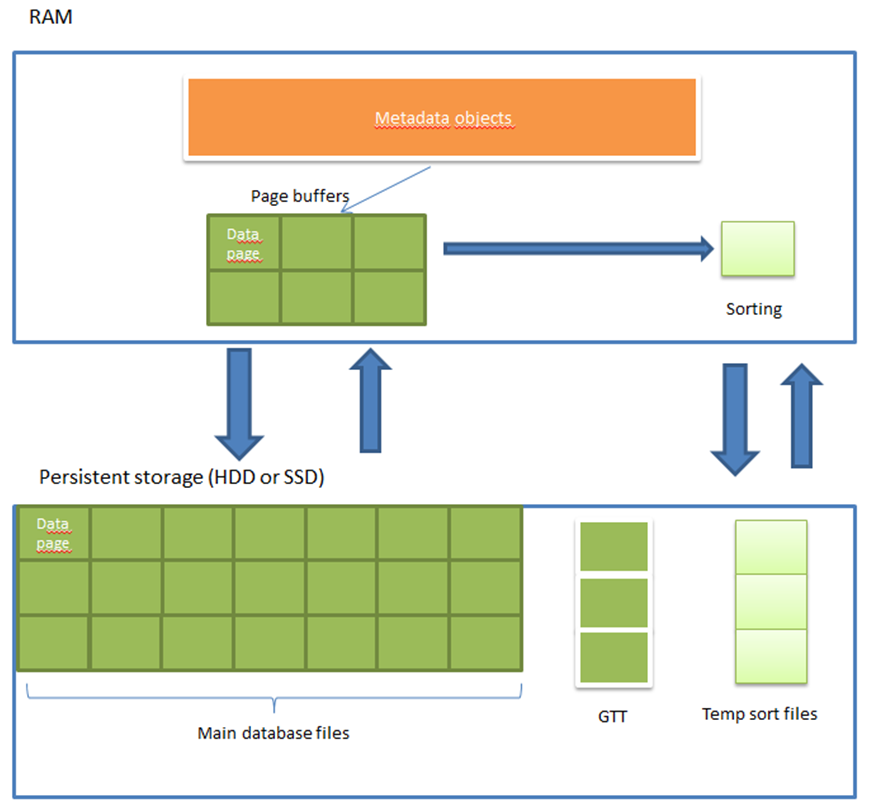
Figura 2. Flussi di dati tra RAM e memoria permanente
Ovviamente, il trasferimento di dati dalla memoria permanente alla RAM e viceversa è l'operazione che richiede più tempo. Crea due flussi di dati: lettura / scrittura di pagine di dati da file di database e lettura / scrittura di file di ordinamento. Dal momento che possono esserci diversi file di ordinamento e possono essere piuttosto grandi, possono creare un carico piuttosto pesante sui dischi, quindi è consigliabile indirizzare questi flussi di input / output su dischi diversi.
Firebird offre due metodi di backup: backup verificato con l'aiuto dell'utilità gbak e backup incrementale non verificato con l'aiuto dell'utilità nbackup.
Ti consigliamo di combinare questi metodi di backup: esegui spesso nbackup (ad esempio, ogni ora, giorno e settimana) e crea una copia di backup verificata ogni notte con l'aiuto di gbak.
Qualunque sia il metodo di backup utilizzato, il file di database viene letto (in tutto o in parte) e viene scritta la copia di backup (completa o incrementale). Le operazioni di scrittura vengono eseguite in sequenza durante il processo di backup, il che significa che i normali dischi rigidi economici con interfaccia SATA (HDD SATA) saranno utili per il backup poiché scrivono in sequenza piuttosto velocemente.
Ora che abbiamo l'idea di come Firebird interagisca con l'hardware, dovremmo soffermarci sui fattori che influenzano la scelta di ogni particolare componente e le sue specifiche.
Quando si sceglie la CPU, è necessario tenere conto delle tre cose seguenti:
Firebird esegue sempre una query su un core in modo che query complesse e scarsamente ottimizzate possano utilizzare un core fino al 100% costringendo altre query a core meno caricati e maggiore è il numero di core, minore è la probabilità che venga utilizzata l'intera CPU e che gli utenti notano qualsiasi peggioramento delle prestazioni nell'applicazione.
Se l'applicazione esegue principalmente semplici brevi query SQL, tutte le query sono ben ottimizzate e non vengono generate query ad hoc (ad esempio, per i report), la CPU non presenterà colli di bottiglia per le prestazioni e puoi scegliere una CPU di fascia bassa con meno nuclei.
Se l'applicazione contiene un generatore di report o molte query lente che restituiscono una grande quantità di dati, è necessaria una CPU con più core.
Il numero di connessioni (utenti attivi) influenza anche la scelta della CPU. Sfortunatamente, anche gli sviluppatori di applicazioni non hanno idea di quante connessioni, query e transazioni siano attive in un determinato momento. Per ottenere informazioni più precise su questo, ti consigliamo di utilizzare lo strumento MON $ Logger di HQbird e fare alcune istantanee mentre è in esecuzione dove vedrai quante connessioni sono effettivamente stabilite.
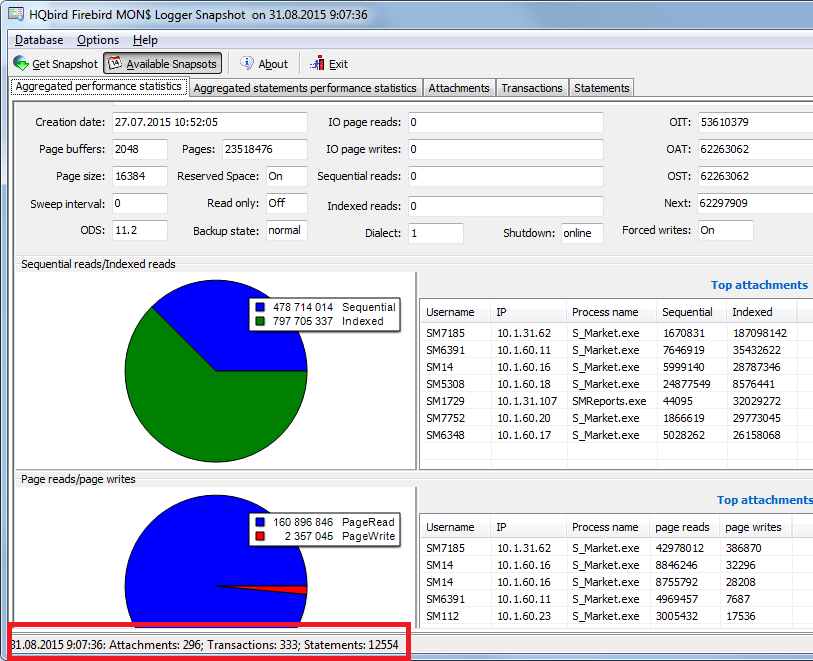
Figura 3. Logger MON $: numero di connessioni
Ad esempio, qui puoi vedere che il numero di connessioni è 296. Ovviamente, in questo caso è troppo ottimistico utilizzare una CPU quad-core, mentre una soluzione a 24 core andrà bene. È inoltre consigliabile contare il numero di query in esecuzione simultaneamente poiché le connessioni potrebbero essere inattive senza alcuna query SQL in esecuzione.
È possibile utilizzare la velocità da 10 a 30 connessioni per 1 core per stimare approssimativamente il numero necessario di core nella CPU. 10 connessioni per core per un'applicazione con query per lo più complicate e lente, 30 connessioni per core per un'applicazione con query per lo più ottimizzate e semplici.
Versione e architettura di Firebird
Se si utilizza Firebird versione 2.5, tenere presente che è necessario utilizzare l'architettura Classic o SuperClassic per poter distribuire l'elaborazione tra più core. Nella versione 2.5, l'architettura SuperServer può utilizzare solo un core per un database, quindi non dovrebbe essere utilizzato in sistemi che consumano molte risorse.
In Firebird versione 3.0, SuperServer, Classic e SuperClassic utilizzano le funzionalità delle CPU multi-core. Firebird 3.0 SuperServer mostra le migliori prestazioni.
Quando scegli la RAM, dovresti prestare attenzione a due cose:
La RAM ECC riduce considerevolmente il numero di errori che si verificano nel corso del lavoro con la memoria e si consiglia vivamente di utilizzarla nei sistemi industriali.
Per calcolare la quantità di memoria, dovremo esaminare le peculiarità di varie architetture di Firebird. Firebird 2.5 Classic e Firebird 3.0 Classic eseguono un processo separato per servire ogni connessione, SuperClassic esegue un thread separato per ogni connessione, ma praticamente con la stessa struttura di consumo di memoria - ogni connessione ha una propria cache di pagina indipendente.
Firebird SuperServer esegue un processo con una cache di pagina per tutte le connessioni.
Pertanto, i seguenti parametri influenzano il consumo complessivo di memoria:
La società IBSurgeon ha eseguito alcuni test e ottenuto una serie di valori ottimali per il numero di pagine nella cache delle pagine di Firebird:
Usando questi test come base, abbiamo creato file di configurazione Firebird ottimizzati per server con una memoria di 4-6 GB. Puoi scaricarli qui: http://ib-aid.com/en/optimized-firebird-configuration/
Di seguito puoi vedere le formule utilizzate per stimare la quantità approssimativa di memoria che sarà richiesta da Firebird. Il consumo effettivo di memoria può differire poiché questa stima non tiene conto della quantità di memoria richiesta per i metadati, per le maschere di bit degli indici, ecc., Che può aumentare il consumo di memoria. Tuttavia, si presume anche che la memoria di ordinamento verrà utilizzata al massimo in tutte le connessioni, cosa che di solito non è il caso.
Quando il database è già in uso, è possibile dare un'occhiata alla quantità media di memoria utilizzata dal processo Firebird (con l'aiuto di TaskManager o ProcessExplorer).
Stima per classico:
Numero di connessioni * ((Numero di pagine nella cache * Dimensioni pagina) + Ordinamento dimensioni cache)
Esempio per Classic: supponiamo di prevedere 100 utenti attivi, la dimensione della pagina del database è impostata su 8 KB e il numero di pagine nella cache della pagina è impostato su 256, la dimensione della cache di ordinamento è aumentata da 8 MB (il valore predefinito per Classic e SuperClassic) a 64 MB:
100 * ((256 * 8 KB) +64) = 6600 MB
Stima per SuperClassic:
Numero di connessioni * (Numero di pagine nella cache * Dimensione pagina) + Ordinamento delle dimensioni della cache
Esempio per SuperClassic: 100 utenti, la dimensione della pagina del database è 8 KB, il numero di pagine nella cache della pagina è 256, la dimensione della cache di ordinamento è 1024 MB
100 * (256 * 8 KB) + 1024 MB = 2024 MB
Stima per SuperServer:
(Numero di pagine nella cache * Dimensioni pagina) + Ordinamento delle dimensioni della cache
Esempio per SuperServer (Firebird 2.5): 1 database, 100 utenti, la dimensione della pagina del database è 8 KB, il numero di pagine nella cache della pagina è 10000, la dimensione della cache di ordinamento è 1024 MB:
(10000 * 8 KB) + 1024 = 1102 MB
Esempio per SuperServer (Firebird 3.0): 1 database, 100 utenti, la dimensione della pagina del database è 8 KB, il numero di pagine nella cache della pagina è 100000, la dimensione della cache di ordinamento è 1024 MB:
(100000 * 8 KB) + 1024 = 1805 MB
"Memoria eccessiva"
Firebird è spesso accusato di un uso inefficace della memoria - quando il processo in esecuzione del server consuma una piccola quantità di RAM e il resto della memoria rimane presumibilmente inutilizzato.
In realtà, non è vero. Questa conclusione sta essenzialmente nell'incomprensione del funzionamento del meccanismo di memorizzazione nella cache di Firebird e nell'imperfezione degli strumenti di monitoraggio del sistema operativo.
Prima di tutto, devi essere assolutamente chiaro che Firebird utilizza ampiamente la cache dei file del sistema operativo. Quando una pagina viene caricata nella cache della pagina Firebird, passa attraverso la cache dei file del sistema operativo. Quando Firebird scarica una pagina dalla sua cache delle pagine, il sistema operativo continua a conservare questo pezzo di database nella sua RAM, purché rimanga memoria libera sufficiente.
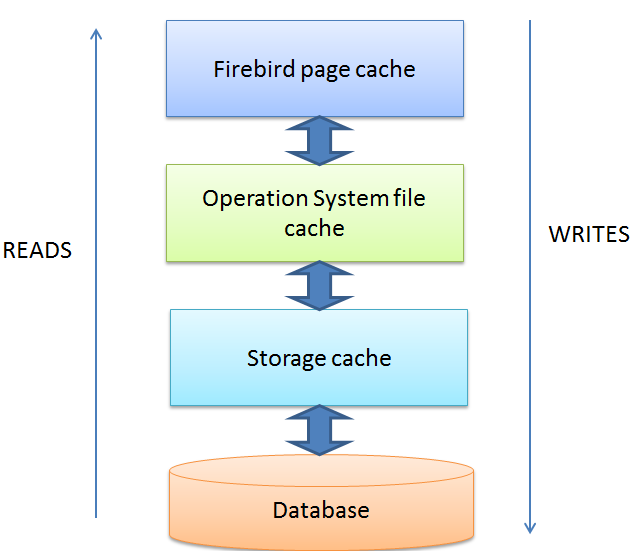
Figura 4. Livelli di cache: Firebird, sistema operativo e memoria
Tuttavia, se lo si guarda, il sistema operativo non mostra la memoria allocata alla cache dei file come utilizzata. Ad esempio, ecco la tipica situazione della distribuzione della memoria quando il server Firebird è in esecuzione, come mostrato da TaskManager:
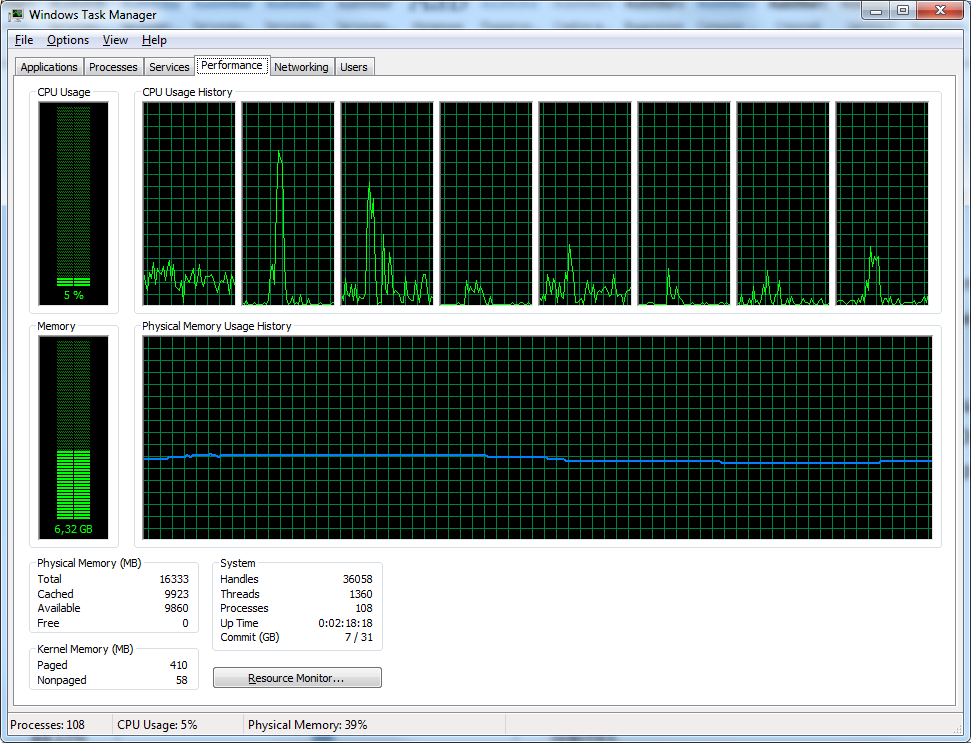
Figura 5. TaskManager non mostra l'utilizzo della cache dei file
Sembra che vengano utilizzati solo 6,3 GB su 16 GB.
Tuttavia, se si utilizza lo strumento RAMMap (da SysInternals di Microsoft), tutto sembra molto più logico:
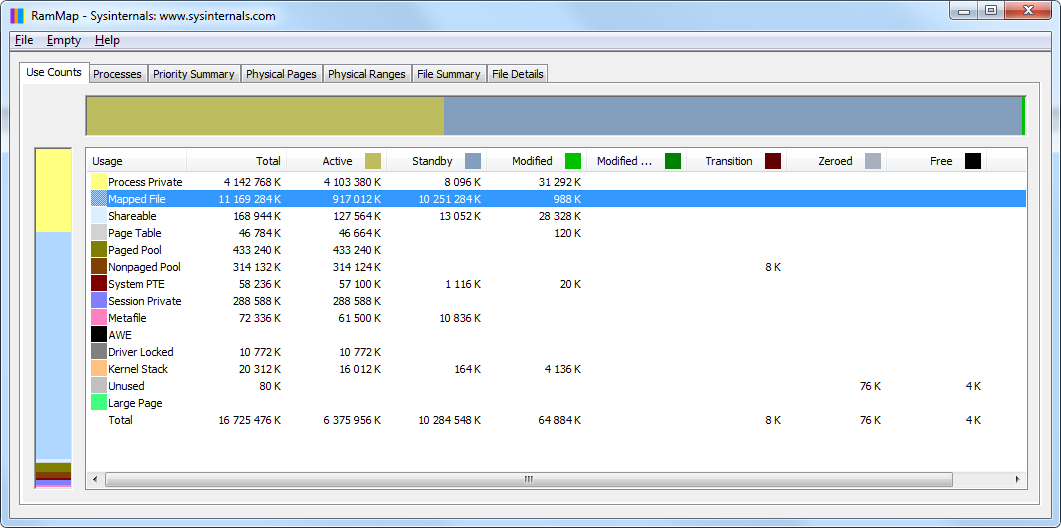
Figura 6. RAMMap mostra i dettagli sull'uso della memoria: i file mappati sono database memorizzati nella cache
I file di database (dbw350_fb252x64.fdb e dbw250_fb252x64.fdb) vengono memorizzati nella cache dal sistema operativo e occupano l'intera memoria dichiarata da TaskManager come libera:
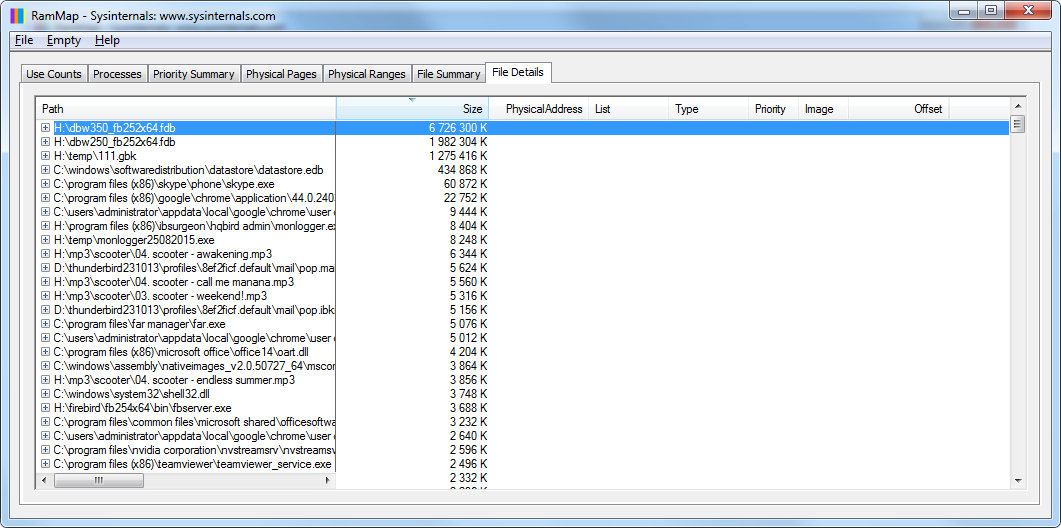
Figura 7. RAMMap: dettagli sull'utilizzo della cache dei file
Quindi concludiamo che il sistema operativo utilizza efficacemente l'intera memoria disponibile per memorizzare nella cache il database fino a caricare completamente il database in memoria.
La corretta configurazione del sottosistema del disco svolge un ruolo importante nella scelta e nella configurazione dell'hardware per Firebird poiché eventuali errori in questo passaggio comporteranno gravi guasti difficili da correggere.
Per ridurre la concorrenza per l'input / output del disco tra le operazioni con il file di database e per ridurre le possibilità di perdita simultanea di database e backup, si consiglia di avere tre diversi dischi (o array di raid): uno per il database, uno per i file temporanei e uno per la creazione e l'archiviazione di copie di backup.
Quando diciamo "dischi separati", significa che i flussi di dati devono passare attraverso canali di input / output diversi. Se si creano tre dischi logici su un disco fisico, non si verificherà alcun aumento delle prestazioni. Tuttavia, se si dispongono tre dischi logici su un dispositivo di archiviazione dati dotato di controller multicanale, le prestazioni saranno molto probabilmente aumentate perché il dispositivo può distribuire flussi di dati tra controller. A volte si dedica un disco separato alla memorizzazione dei file del sistema operativo e si dice che il file di scambio del sistema operativo aumenti le prestazioni.
SSD è la scelta migliore per lavorare con un database perché garantisce un ottimo ridimensionamento durante l'input / output parallelo. È indispensabile utilizzare dischi aziendali con un numero maggiore di cicli di lettura / scrittura, altrimenti è altamente possibile che si perdano dati a causa di un errore di SSD.
Qualche tempo fa, gli SSD erano soggetti a una maggiore usura nel caso in cui sul disco rimanesse poco spazio libero (meno del 30%). In parole povere, ogni modifica su un SSD viene scritta in una nuova cella libera, quindi la mancanza di spazio libero ha portato all'aumento dell'usura delle celle rimaste libere e alla durata più breve del disco.
I produttori di moderni controller SSD dichiarano che questo problema è stato risolto spostando preventivamente i dati statici e ora l'usura delle celle è più o meno livellata. Tuttavia, le specifiche esatte e gli algoritmi di funzionamento degli SSD sono tenuti segreti dai produttori, pertanto consigliamo comunque di lasciare libero il 30% dello spazio sugli SSD, nonché di ridurre la durata prevista e pianificare di sostituirli non meno di una volta ogni tre anni.
Supponiamo che la dimensione del database sia attualmente di 100 GB, che aumenta di 1 GB al mese. In questo caso, non è necessario acquistare un SSD di dimensioni minime (120 GB), ma è meglio scegliere il dispositivo successivo nella linea di prodotti: 250 GB. Allo stesso tempo, l'acquisto di un SSD da 512 gigabyte sarà uno spreco di denaro poiché è consigliabile sostituire il disco in tre anni.
La migliore pratica è dedicare un SSD esclusivamente alla collaborazione con il database poiché qualsiasi operazione di input / output riduce la durata dei dischi.
Poiché i file temporanei vengono visualizzati sul disco solo quando non vi è sufficiente quantità di RAM, il modo migliore è ovviamente evitare questa situazione del tutto. È possibile valutare il numero e le dimensioni dei file temporanei in un sistema di produzione solo monitorando la cartella con file temporanei. FBDataGuard dal pacchetto di distribuzione di HQbird esegue questo tipo di monitoraggio. Una volta che sai quanti file di ordinamento temporanei vengono creati sul disco e quando vengono creati, sarai in grado di aumentare la quantità di RAM e modificare la configurazione in firebird.conf.
In ogni caso, Firebird richiede di specificare la cartella in cui verranno archiviati i file temporanei. Di solito, l'impostazione predefinita rimane invariata, ovvero viene utilizzata la cartella del sistema operativo per i file temporanei. Se la RAM libera è sufficiente, questa è una buona scelta.
Tuttavia, esiste un altro problema importante relativo alla posizione dei file temporanei sul disco: si stanno creando indici quando si ripristina una copia di backup verificata (creata con l'utilità gbak). Quando viene creato un indice, viene creato anche un file temporaneo contenente tutte le chiavi di questo indice. Se il database è piuttosto grande, anche la dimensione dell'indice per alcune tabelle di grandi dimensioni può essere piuttosto grande. Ad esempio, l'indice della tabella più grande che comprende 3,2 miliardi di record in un database da 1 terabyte è 29 GB, ma sono stati necessari 180 GB di spazio libero per creare questo indice:
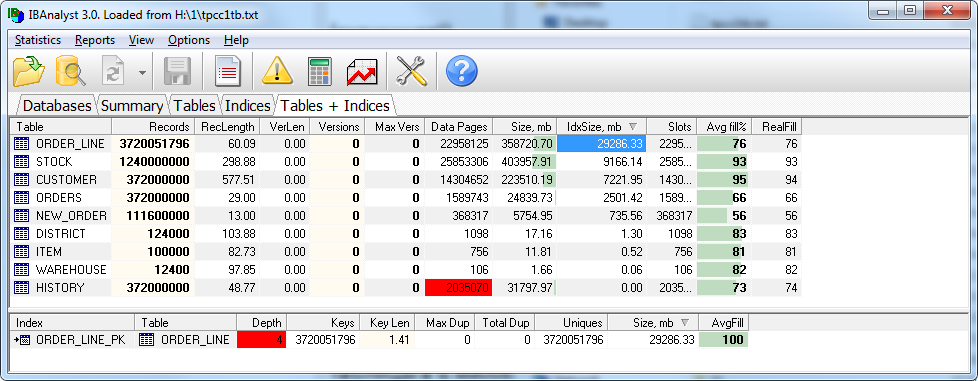
Per evitare la mancanza di spazio libero sul disco di sistema, è possibile specificare un altro disco come spazio riservato aggiuntivo in firebird.conf:
TempDirectories = C: \ temp; H: \ Temp
Se non c'è spazio sul primo disco, Firebird continuerà a utilizzare il secondo disco per i file temporanei e così via.
I normali HDD con interfaccia SATA o nSAS andranno bene per la creazione e l'archiviazione di copie di backup. Assicurano operazioni di scrittura e lettura sequenziali veloci per i file di backup e sono abbastanza economici da non risparmiare sulla loro dimensione e conservare diverse copie di backup.
I dischi per le copie di backup devono sempre disporre di ulteriore spazio libero su di essi: la dimensione dell'ultima copia di backup + 10%. In questo caso, è possibile creare una nuova copia di backup, assicurarsi che il processo di backup sia terminato correttamente (questo processo potrebbe richiedere diverse ore per un database con una dimensione di diversi terabyte) e solo successivamente eliminare la copia di backup precedente.
Se si elimina la copia di backup precedente prima di crearne una nuova, è possibile che non venga creata una nuova copia di backup mentre quella precedente verrà già eliminata e il database verrà danneggiato, ad esempio a causa di un errore del disco.
Se si utilizza il metodo di backup consigliato in precedenza (la combinazione di backup incrementale a tre livelli e backup verificato una volta al giorno che memorizza solo una copia più recente), utilizzare la seguente formula per calcolare lo spazio minimo per il backup:
Database_size * 3 + 0.2 * Database_size
Considera il seguente esempio di calcolo dello spazio necessario per il backup:
Supponiamo di avere un database di 100 GB per il quale archiviamo un backup incrementale a tre livelli (settimana-giorno-ora - una copia ciascuno) e una copia del backup giornaliero verificato. In questo caso, le copie di backup occuperanno il seguente spazio:
Totale: 316 GB.
! la dimensione del file incrementale di primo livello o superiore dipende dal numero di pagine modificate dal momento in cui nbackup è stato eseguito l'ultima volta. La dimensione di questi file può essere determinata solo sperimentalmente poiché la quantità di modifiche in un database dipende dalle applicazioni.
Ovviamente, la stima dello spazio per il backup dovrebbe tenere conto del possibile aumento anomalo delle dimensioni del database e corrispondentemente aumentare la quantità di spazio libero o altrimenti il processo di backup potrebbe essere interrotto inaspettatamente a causa della mancanza di spazio.
Naturalmente, gli strumenti di backup intelligenti (FBDataGuard di HQbird) noteranno la mancanza di spazio per le copie di backup e invieranno il messaggio corrispondente all'amministratore.
Un SSD potrebbe rivelarsi una soluzione troppo costosa o il database potrebbe essere troppo grande e dovrai usare metodi meno costosi. In questo caso, è necessario utilizzare un HDD con l'interfaccia SAS. Se ciò non è possibile, utilizzare i dischi SATA con l'interfaccia nSAS o l'opzione più economica: i normali dischi SATA.
Per aumentare la velocità (e anche l'affidabilità - vedi sotto) dei dischi rigidi, è necessario combinarli in RAID10. RAID10 è una combinazione di blocchi con mirroring (RAID1) e striping (RAID0). Un controller RAID valido e ben configurato con cache di grandi dimensioni è una valida alternativa agli SSD.
Naturalmente, è necessario aumentare l'affidabilità del sottosistema del disco combinando i dischi nell'aumento del RAID in tutte le varianti sopra menzionate (ad eccezione del disco dedicato esclusivamente ai file temporanei).
Ad eccezione del fatto che è possibile utilizzare PCI Express 3.0 per combinare SSD in RAID 10 perché il throughput di questo bus è già di 16 gigabit al secondo e superiori.
Prima di tutto, dovresti assicurarti che ci sia un'unità batteria di backup (BBU) correttamente caricata nel RAID. Se non è presente tale batteria, la maggior parte dei RAID passa alla modalità di scrittura sicura (la cache del disco è completamente disabilitata) che offre una velocità di input / output inferiore rispetto a un normale disco SATA!
Questo fatto causa la maggior parte dei messaggi frustrati al supporto tecnico degli utenti che hanno acquistato un server costoso e hanno scoperto che funziona lentamente
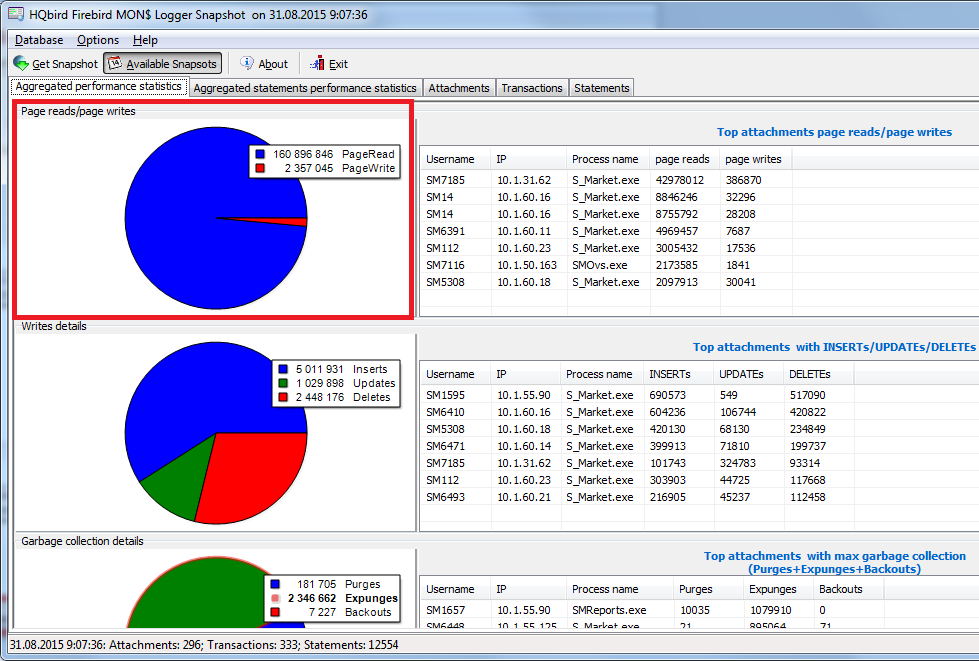
Figura 8. HQbird MON $ Logger: rapporto lettura / scrittura
Come puoi vedere, ci sono molte più operazioni di lettura che operazioni di scrittura in questo esempio, quindi ha senso configurare il controller RAID per l'80% delle operazioni di lettura e il 20% delle operazioni di scrittura.
I depositi integrati sono diventati popolari di recente. Includono un array di dischi personalizzabile in modo flessibile (tutti i tipi di RAID) con funzionalità di cache avanzate. Di solito, le SAN dispongono di numerosi controller di input / output, che consentono di servire più server contemporaneamente e di funzionare abbastanza velocemente.
Molte organizzazioni acquistano SAN e le usano nel loro lavoro con i database Firebird. Se una SAN è configurata correttamente, è possibile ottenere buone prestazioni. È necessario tenere conto dei seguenti problemi se si utilizza SAN:
Spesso le SAN vengono utilizzate come "due server - una SAN" per creare un cluster a prova di errore. Va notato che un tale cluster può risolvere i problemi relativi solo a guasti hardware su uno dei server passando al secondo server contemporaneamente. Se il problema è correlato alla SAN o al database stesso, questa soluzione non sarà di aiuto.
Per creare una soluzione realmente a prova di errore, è necessario utilizzare soluzioni che replicano i dati tra due istanze di database. Puoi contattare support@p-soft.biz per scoprire altre soluzioni disponibili per Firebird.
Riassumiamo le conclusioni e le raccomandazioni per Firebird relative all'hardware.